Sortowanie przez scalanie
Sortowanie przez scalanie należy do algorytmów, które wykorzystują metodę „dziel i zwyciężaj„. Złożoność algorytmu wynosi
n⋅log n
a więc jest on znacznie wydajniejszy niż sortowanie bąbelkowe, przez wstawianie czy przez selekcję, gdzie złożoność jest kwadratowa. Żeby zrozumieć zasadę działania przyjrzyjmy się najpierw dwóm posortowanym tablicom:
tablica 1: 2 3 7 9 10
tablica 2: 1 3 4 8 11
Zauważmy, że możemy liniowo scalić te dwa ciągi liczb i uzyskać jedną posortowaną tablicę postępując ze schematem:
- ustawiamy liczniki na początku tablic posortowanych,
- następnie porównujemy elementy i mniejszy lub równy element wskakuje jako pierwszy w scalonej tablicy,
- zwiększamy licznik w tej tablicy, z której „zabraliśmy element”,
- czynność powtarzamy aż do wyczerpania danych z obu tablic.

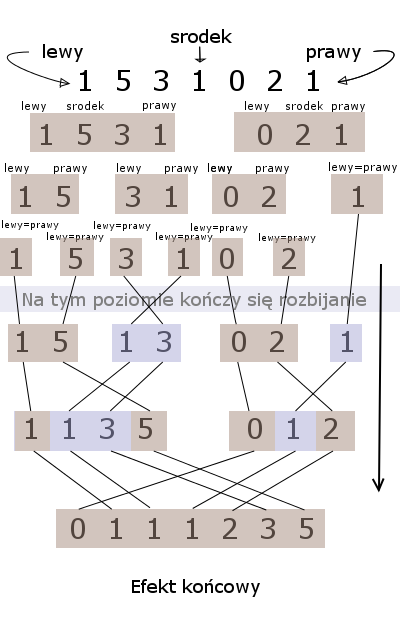
A więc najpierw musimy doprowadzić do sytuacji, gdzie będziemy mieli dwie posortowane tablice. Dzielimy nasz zbiór liczb na dwie części, następnie każdą z nich także dzielimy na dwie części, czynność powtarzamy do momentu otrzymania podtablic jednoelementowych (wykonujemy to rekurencyjnie). Ponieważ zbiór jednoelementowy jest już posortowany możemy przejść do scalania. W ten sposób powstają nam coraz to większe posortowane zbiory, aż w rezultacie otrzymamy oczekiwany efekt – ciąg posortowanych elementów.
Zalety algorytmu
- prostota implementacji
- wydajność
- stabilność
- algorytm sortuje zbiór n-elementowy w czasie proporcjonalnym do liczby
n⋅log n
bez względu na rodzaj danych wejściowych
Wady algorytmu
- podczas scalania potrzebny jest dodatkowy obszar pamięci przechowujący kopie podtablic do scalenia
Schemat:
Implementacja algorytmu przez scalanie: